

Стандартные типы данных в C++
Оглавление
Запись занятия
Двоичная запись числа wiki
В двоичной системе счисления числа записываются с помощью двух символов (0 и 1). Чтобы не путать, в какой системе счисления записано число, его снабжают указателем справа внизу. Например, число в десятичной системе 510, в двоичной 1012. Иногда двоичное число обозначают префиксом 0b, например 0b101.
В двоичной системе счисления (как и в других системах счисления, кроме десятичной) знаки читаются по одному. Например, число 1012 произносится «один ноль один».
Натуральные числа
Натуральное число, записываемое в двоичной системе счисления как (an-1an-2… a1a0)2, имеет значение:
(an-1an-2... a1a0)2 = a0 + 2a1 + 22a2 + ... + 2n-1an-1
где:
n — количество цифр (знаков) в числе,
ak — значения цифр из множества {0,1},
k — порядковый номер цифры
А как их хранить?
В компьютерах числа хранятся в двоичной записи. Проще всего хранить натуральные числа: нужно лишь запомнить последовательность из нулей и единиц. К сожалению, мы не можем хранить неограниченно большое число, ниже вы увидите таблицу для ограничений типов в C++:
| Тип данных | Размер, бит | Ограничения в степенях двойки | Примерные ограничения |
|---|---|---|---|
| unsigned char | 8 | [0; 28 - 1] | [0; 255] |
| unsigned short | 16 | [0; 216 - 1] | [0; 65'535] |
| unsigned int | 32 | [0; 28 - 1] | [0; 4,2 * 109] |
| unsigned long long | 64 | [0; 264 - 1] | [0; 1,8 * 1019] |
Например, если вы напишете код
1
unsigned char x = 11;
То в памяти 11 будет храниться как 00001011.
Отрицательные целые числа
Первая идея, которая приходит в голову - это зарезервировать один бит под знак (например, старший). Такой подход называется “прямой код”, и при его использовании возникнет сразу две проблемы:
- Числа
00000000и10000000обозначают 0 и -0. То есть есть два обозначение одного и того же числа 0. - Другая проблема - это арифметические операции. Оказывается, их очень неудобно реализовывать, если старший бит будет отвечать за знак.
Но есть и несколько плюсов:
- Достоинства представления чисел с помощью кода с дополнением до единицы
- Простое получение кода отрицательных чисел.
- Из-за того, что 0 обозначает +, коды положительных чисел относительно беззнакового кодирования остаются неизменными. Количество положительных чисел равно количеству отрицательных.
Всё же оказывается, что данный подход не применим для архитектуры компьютера, поэтому люди придумали решение, именуемое “дополнительный код”:
Будем хранить “остатки” от деления на 28 (или нужную степень двойки). Таким образом, если мы хотим сохранить число x от 0 до 127, то мы будем хранить именно его. Для чисел x из интервала [-128; -1] будем хранить его остаток от деления на 256, что эквивалентно числу 256 + x. Таким образом мы решили сразу две проблемы (вторая проблема решена, автоматически, так как арифметика остатков очень простая).
Таким образом, если вы напишете
1
char x = -2;
То в x будет записан в памяти как 256 - 2 = 254: 11111110
Преимущества данного подхода:
- Возможность заменить арифметическую операцию вычитания операцией сложения и сделать операции сложения одинаковыми для знаковых и беззнаковых типов данных, что существенно упрощает архитектуру процессора и увеличивает его быстродействие.
- Нет проблемы двух нулей.
Недостатки:
- Ряд положительных и отрицательных чисел несимметричен, но это не так важно: с помощью дополнительного кода выполнены гораздо более важные вещи, желаемые от способа представления целых чисел.
- В отличие от сложения, числа в дополнительном коде нельзя сравнивать как беззнаковые, или вычитать без расширения разрядности.
| Тип данных | Размер, бит | Ограничения в степенях двойки | Примерные ограничения |
|---|---|---|---|
| char | 8 | [-27; 27 - 1] | [-128; 127] |
| short | 16 | [-215; 215 - 1] | [-32768; 32767] |
| int | 32 | [-231; 231 - 1] | [-2,1 * 109; 2,1 * 109] |
| long long | 64 | [-263; 263 - 1] | [-9 * 1018; 9 * 1018] |
Упражнения на битовые операции
Теперь вы формально знаете, как хранятся числа в двоичной записи. Настало время этим воспользоваться.
Битовые операции в C++
Есть несколько видов битовых операций: логические или, и, ксор и отрицание. Они выполняют логические операции над каждым битом независимо. На C++ это будет соответственно так:
1
2
3
4
5
6
char a = 0b0011; // 3
char b = 0b0101; // 5
char c = a | b; // 0011 | 0101 = 0111 = 7
char d = a & b; // 0011 & 0101 = 0001 = 1
char e = a ^ b; // 0011 ^ 0101 = 0110 = 6
char g = ~a; // ~00000011 = 11111100 = -4
Кроме того, часто пригождается еще и операции битового сдвига влево и вправо соответственно:
1
2
char h = a << 2; // 11 << 2 = 1100 = 12
char i = b >> 2; // 101 >> 2 = 1
С помощью таких примитивов предлагается решить несколько упражнений:
Как получить 2n?
Решение
1
2
int x = 1 << n;
long long y = 1LL << n;
Как убрать последнюю единицу в битовой записи?
Решение
1
2
int x = 228;
int y = x & (x - 1); // x без последней единицы в битовой записи
Как убрать группу из единиц на конце числа?
1
2
int x = 7 + 32;
int y = x & (x + 1); // x без группы из единиц на конце числа, т.е. 32
Вещественные числа wiki
Это боль и страдания. И когда мы дойдем до геометрии, то вы поймете, что даже имея правильное решение легко получить WA на задаче. Чтобы лучше понимать проблему и более грамотно работать с вещественными числами, стоит знать как они устроены.
Вещественные числа обычно представляются в виде чисел с плавающей запятой. Числа с плавающей запятой — один из возможных способов представления действительных чисел, который является компромиссом между точностью и диапазоном принимаемых значений, его можно считать аналогом экспоненциальной записи чисел, но только в памяти компьютера.
Число с плавающей запятой состоит из набора отдельных двоичных разрядов, условно разделенных на так называемые знак (англ. sign), порядок (англ. exponent) и мантиссу (англ. mantis). В наиболее распространённом формате (стандарт IEEE 754) число с плавающей запятой представляется в виде набора битов, часть из которых кодирует собой мантиссу числа, другая часть — показатель степени, и ещё один бит используется для указания знака числа (0 — если число положительное, 1 — если число отрицательное). При этом порядок записывается как целое число в коде со сдвигом, а мантисса — в нормализованном виде, своей дробной частью в двоичной системе счисления. Вот пример такого числа из 16 двоичных разрядов:
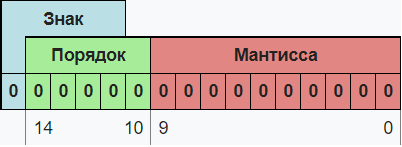
Знак — один бит, указывающий знак всего числа с плавающей точкой. Порядок и мантисса — целые числа, которые вместе со знаком дают представление числа с плавающей запятой в следующем виде:
$(−1)^S×M×B^E$, где $S$ — знак, $B$ — основание, $E$ — порядок, а $M$ — мантисса. Десятичное число, записываемое как $ReE$, где $R$ — число в полуинтервале $[1;10)$, $E$ — степень, в которой стоит множитель $10$; в нормализированной форме модуль $R$ будет являться мантиссой, а $E$ — порядком, а $S$ будет равно $1$ тогда и только тогда, когда $R$ принимает отрицательное значение. Например, в числе $−2435e9$
$S = 1, B = 10, M = 2435, E = 9$ Порядок также иногда называют экспонентой или просто показателем степени.
При этом лишь некоторые из вещественных чисел могут быть представлены в памяти компьютера точным значением, в то время как остальные числа представляются приближёнными значениями.
Диапазон значений чисел с плавающей запятой
Диапазон чисел, которые можно записать данным способом, зависит от количества бит, отведённых для представления мантиссы и показателя. Пара значений показателя (когда все разряды нули и когда все разряды единицы) зарезервирована для обеспечения возможности представления специальных чисел. К ним относятся ноль, значения $NaN$ (Not a Number, “не число”, получается как результат операций типа деления нуля на ноль) и $±∞$.
| Название типа переменной в C++ | Диапазон значений | Бит в мантиссе | Бит на переменную |
|---|---|---|---|
| float | -3,4×1038..3,4×1038 | 23 | 32 |
| double | -1,7×10308..1,7×10308 | 53 | 64 |
| long double | -3,4×104932..3,4×104932 | 65 | 80 |
Данная таблица только лишь ПРИМЕРНО указывает границы допустимых значений, без учета возрастающей погрешности с ростом абсолютного значения и существования денормализованных чисел.
В действительности же, распределение чисел, которые вы можете хранить будет сконцентроровано возде нуля, а на границах числа будут очень разрежены. Если не смотреть на значения, по оси X, то распределение будет примерно таким:
